多亏了开放的万维网协议,任何人都能轻易的修改网页呈现方式(比如用户脚本与用户样式),甚至下载原本网页运营不打算提供的内容。
这里介绍一款浏览器插件,叫 DownThemAll! 支持三大主流浏览器(Chrome Firefox 与 Opera)
在下载菜单里的筛选器中,选择图片格式,就能下载所有的图片。其他格式也很容易选择,进阶用法还有正则表达式。
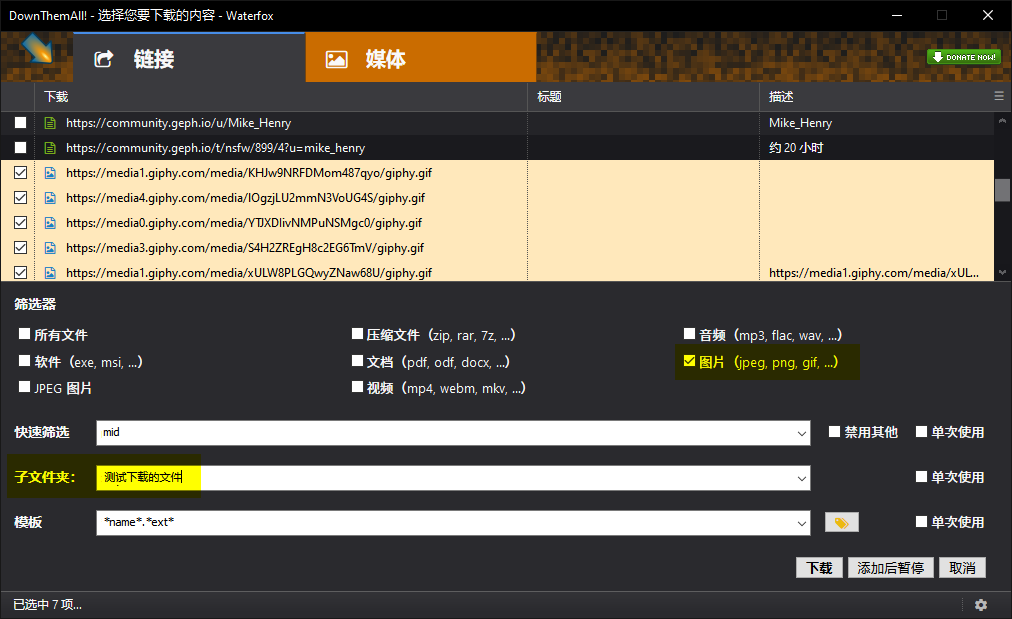
如果图片数量众多,自定义一个合适名称的子文件夹,会对整理文件有帮助
多亏了开放的万维网协议,任何人都能轻易的修改网页呈现方式(比如用户脚本与用户样式),甚至下载原本网页运营不打算提供的内容。
这里介绍一款浏览器插件,叫 DownThemAll! 支持三大主流浏览器(Chrome Firefox 与 Opera)
在下载菜单里的筛选器中,选择图片格式,就能下载所有的图片。其他格式也很容易选择,进阶用法还有正则表达式。
如果图片数量众多,自定义一个合适名称的子文件夹,会对整理文件有帮助
我用了一下,可能是我表述沒到位,我的需求是爬取不同頁面的圖片,例如點擊下一頁,控制台中的網絡圖片就會增加一個,再點擊下一頁,又增加一個,等點到最後一頁,所有圖片都加載完,然後一起下載。
並非單個頁面上的所有圖片。
有没有测试用的网页,比如跟这个网站相似的网站,或者这些图片的 URL 是否有规律?
如果图片 URL 有规律,那么可以使用新建下载,进行批量下载。
比如这是下载 test.com/images1.jpg 到 test.com/images20.jpg 的写法。
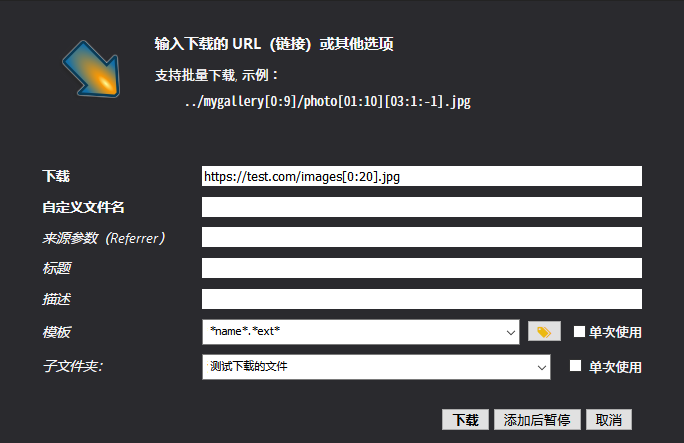
沒有規律。這個方法不行。
也许需要实际网址,才能让大家尝试解决 
說了沒有規律,中間有大段都是隨機數生成的,有規律根本不用這個下載器,自己用excel寫一串即可。
不過還是感謝你幫忙想解決方案。
如果【下一页】的 URL 是有规律的,可能可以靠 图片助手(ImageAssistant) 批量图片下载器 这个 Chrome 插件进行深度嗅探。
或者靠【宏】自动化的抓取图片,iMacros for Chrome
如果给出这个网站,或者类似的网站,应该就更容易解决了。
找到了鏈接規律,但又出現了一個新問題,就是用這個插件下載的圖片,會按照下載時間自動編號為1234等命名。但正批圖片其實是有自己的前後順序的,類似一本圖書,只是沒有頁碼,那麼如果先下載到本地是第四頁但卻會被命名為1,整批圖片的原始順序就會被打亂。必須人工校對,失去了自動化的意義。
問題依然未解決,就是下載後的命名問題,導致圖片順序出現錯亂。上層已經說明。
現在想到一個解決方案,由於每個鏈接地址中內含頁碼信息,同時控制台也會顯示圖片大小。如果同時獲得以上兩種信息,那麼根據下載後的圖片大小,可以推導出原鏈接地址,從而進行重新排序。
另外還有一個解決方案,就是通過某方式直接獲取下載圖片的原鏈接信息,但目前還不如如何獲取?
請問這兩種方案是否可行?
有的下载程序能够以文件的 URL 作为文件名,所以可能能设置上。
另外的一种方法我不太理解。
該軟件的模板有選項可以用url做文件名,但實際下載過程中,由於用url命名的文件名中包含斜杠/,被windows文件系統拒絕寫入。
图片的 URL 的区别是否在斜杠/后,如果在斜杠/后,使用 {filename} 就能命名出合适的文件名。
{filename} 不行吧, {filename} 命名就會出現我說的那種按照下載時間命名的錯誤。
整個文檔我都看了一下,好像通過軟件內部的設置是無法解決的。
 那么大概只有宏与自制 User.js 能够解决了。
那么大概只有宏与自制 User.js 能够解决了。
你的意思是使用類似按鍵精靈那種自動軟件來重複動解決麼?
ok,我貌似找到解決方案了,軟件內部提供了導出link信息的功能。
我 不喜歡 用 Windows
问题不大,浏览器插件都是跨平台的。

{kind=link}
{kind=link}